Matplotlib e Seaborn: visualização de dados com Python
Crie gráficos profissionais com Matplotlib e Seaborn. De linhas simples a dashboards completos.
Por que visualizar dados?
Números em uma tabela contam uma história, mas um gráfico a torna impossível de ignorar. A visualização de dados transforma informações brutas em imagens que revelam padrões, tendências e anomalias em segundos.
Considere este exemplo: se alguém mostra uma tabela com 1000 linhas de vendas mensais, você demora para encontrar padrões. Mas se essa mesma informação aparece como um gráfico de linha, você vê imediatamente se as vendas estão subindo, descendo ou oscilando.
Python tem duas bibliotecas principais para visualização:
| Biblioteca | Papel | Nível de controle |
|---|---|---|
| Matplotlib | Base da visualização em Python | Total (cada detalhe é configurável) |
| Seaborn | Camada sobre Matplotlib com visual moderno | Alto (gráficos bonitos com menos código) |
Matplotlib: o básico
Matplotlib segue uma estrutura simples: você cria uma figura (a tela), adiciona eixos (o gráfico) e exibe o resultado.
import matplotlib.pyplot as plt
# Dados
meses = ["Jan", "Fev", "Mar", "Abr", "Mai", "Jun"]
vendas = [1200, 1500, 1350, 1800, 2100, 1950]
# Criar o grafico
plt.plot(meses, vendas)
plt.title("Vendas Mensais - 2026")
plt.xlabel("Mes")
plt.ylabel("Vendas (R$)")
plt.show()
A convenção é importar matplotlib.pyplot como plt. O método plt.show() exibe o gráfico na tela. No Jupyter Notebook, o gráfico aparece diretamente na célula.
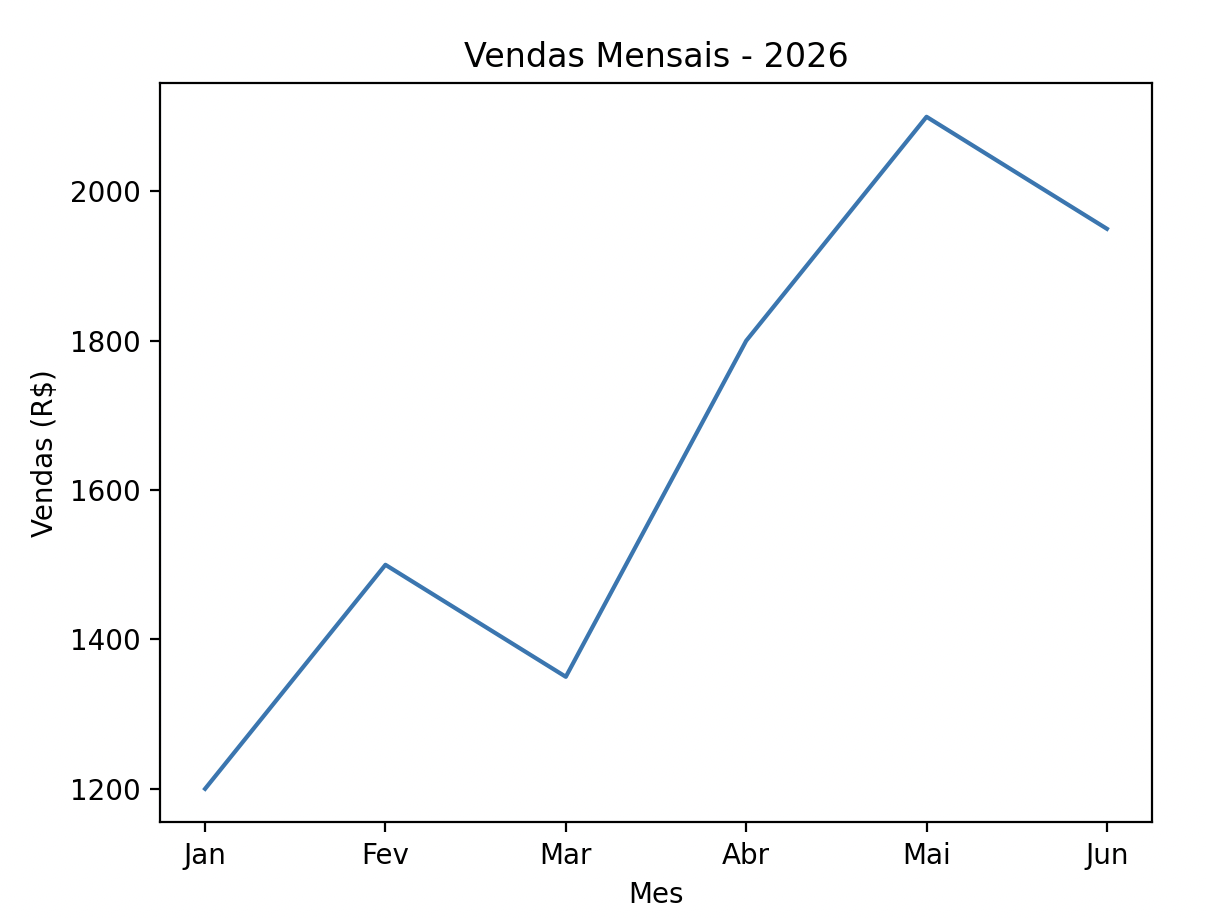
Gráficos de linha
Gráficos de linha são perfeitos para mostrar tendências ao longo do tempo:
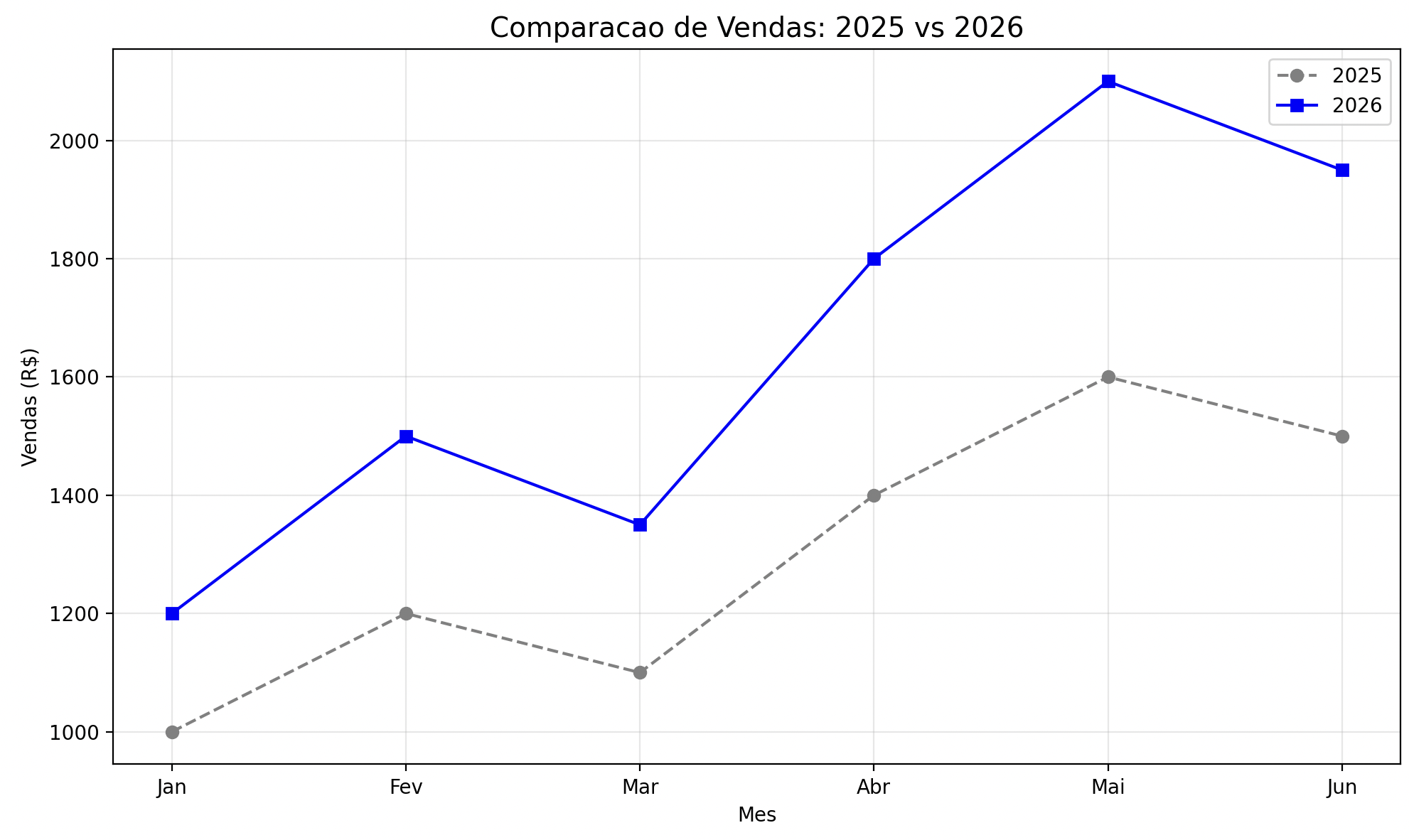
import matplotlib.pyplot as plt
meses = ["Jan", "Fev", "Mar", "Abr", "Mai", "Jun"]
vendas_2025 = [1000, 1200, 1100, 1400, 1600, 1500]
vendas_2026 = [1200, 1500, 1350, 1800, 2100, 1950]
plt.figure(figsize=(10, 6))
plt.plot(meses, vendas_2025, marker="o", linestyle="--", color="gray", label="2025")
plt.plot(meses, vendas_2026, marker="s", linestyle="-", color="blue", label="2026")
plt.title("Comparacao de Vendas: 2025 vs 2026", fontsize=14)
plt.xlabel("Mes")
plt.ylabel("Vendas (R$)")
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
Parâmetros úteis do plot():
| Parâmetro | Descrição | Exemplos |
|---|---|---|
marker |
Marcador nos pontos | "o", "s", "^", "D" |
linestyle |
Estilo da linha | "-", "--", "-.", ":" |
color |
Cor da linha | "blue", "red", "#FF5733" |
linewidth |
Espessura da linha | 1, 2, 3 |
label |
Rótulo para a legenda | "Vendas 2026" |
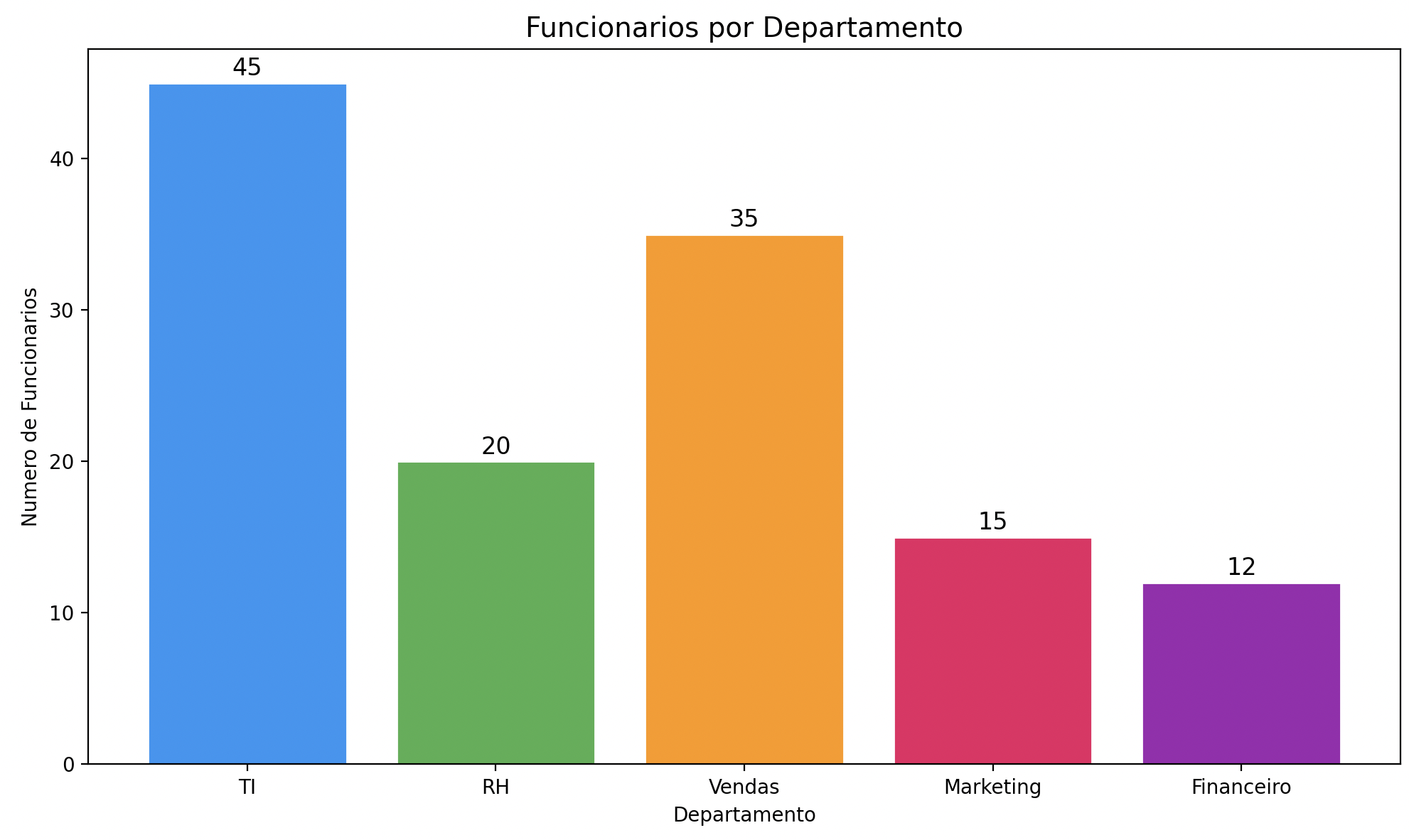
Gráficos de barra
Ideais para comparar categorias:
import matplotlib.pyplot as plt
departamentos = ["TI", "RH", "Vendas", "Marketing", "Financeiro"]
funcionarios = [45, 20, 35, 15, 12]
cores = ["#2196F3", "#4CAF50", "#FF9800", "#E91E63", "#9C27B0"]
plt.figure(figsize=(10, 6))
barras = plt.bar(departamentos, funcionarios, color=cores, edgecolor="white")
# Adicionar valores em cima de cada barra
for barra in barras:
altura = barra.get_height()
plt.text(barra.get_x() + barra.get_width() / 2, altura + 0.5,
str(int(altura)), ha="center", fontsize=12)
plt.title("Funcionarios por Departamento", fontsize=14)
plt.xlabel("Departamento")
plt.ylabel("Numero de Funcionarios")
plt.tight_layout()
plt.show()
Para barras horizontais, use plt.barh():
import matplotlib.pyplot as plt
departamentos = ["TI", "RH", "Vendas", "Marketing", "Financeiro"]
funcionarios = [45, 20, 35, 15, 12]
plt.figure(figsize=(10, 6))
plt.barh(departamentos, funcionarios, color="#2196F3")
plt.title("Funcionarios por Departamento")
plt.xlabel("Numero de Funcionarios")
plt.tight_layout()
plt.show()
Gráficos de dispersão (scatter)
Perfeitos para explorar a relação entre duas variáveis:
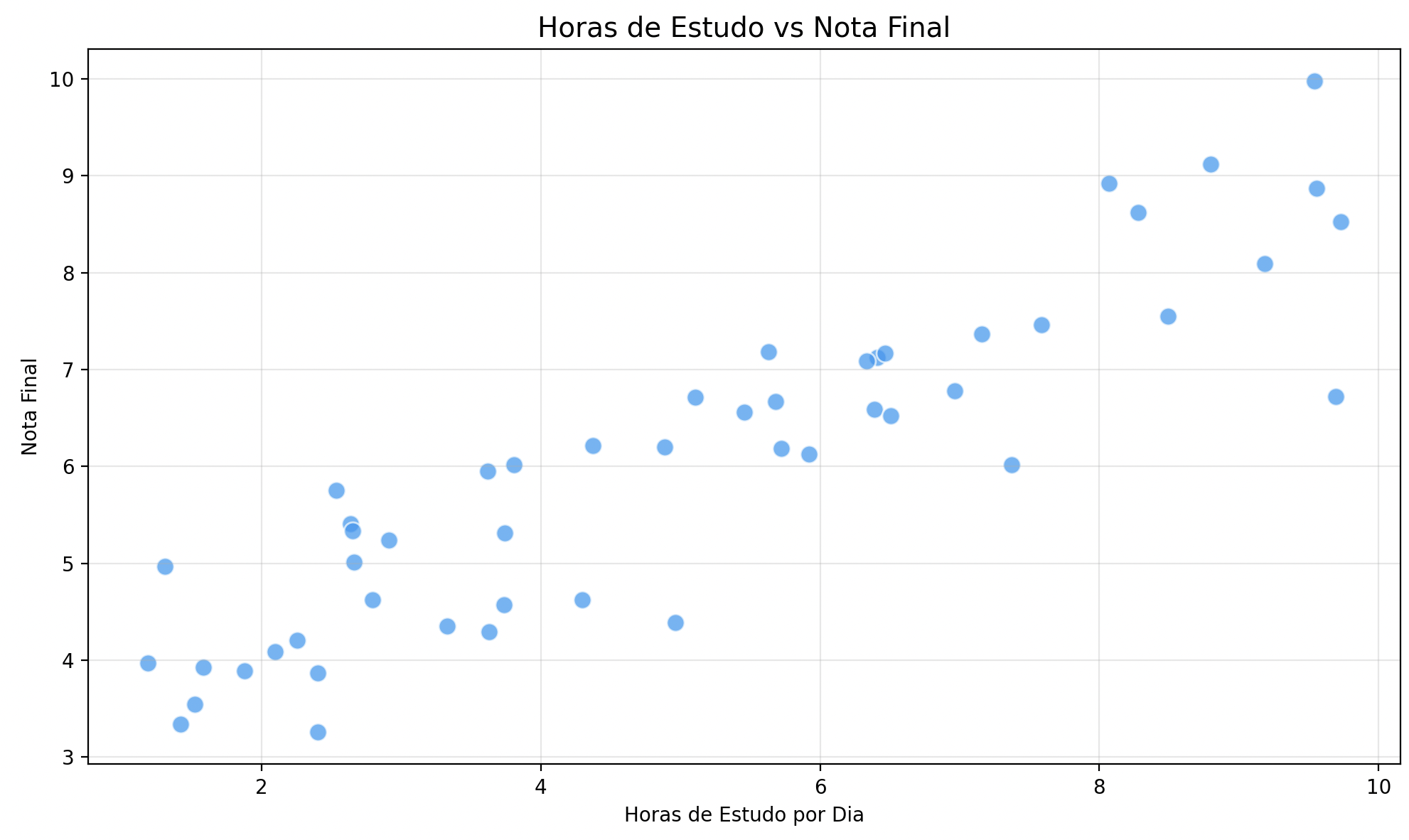
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(42)
horas_estudo = np.random.uniform(1, 10, 50)
notas = 3 + horas_estudo * 0.6 + np.random.normal(0, 0.8, 50)
notas = np.clip(notas, 0, 10)
plt.figure(figsize=(10, 6))
plt.scatter(horas_estudo, notas, alpha=0.7, color="#2196F3", edgecolors="white", s=80)
plt.title("Horas de Estudo vs Nota Final", fontsize=14)
plt.xlabel("Horas de Estudo por Dia")
plt.ylabel("Nota Final")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
Histogramas
Mostram a distribuição de uma variável numérica:
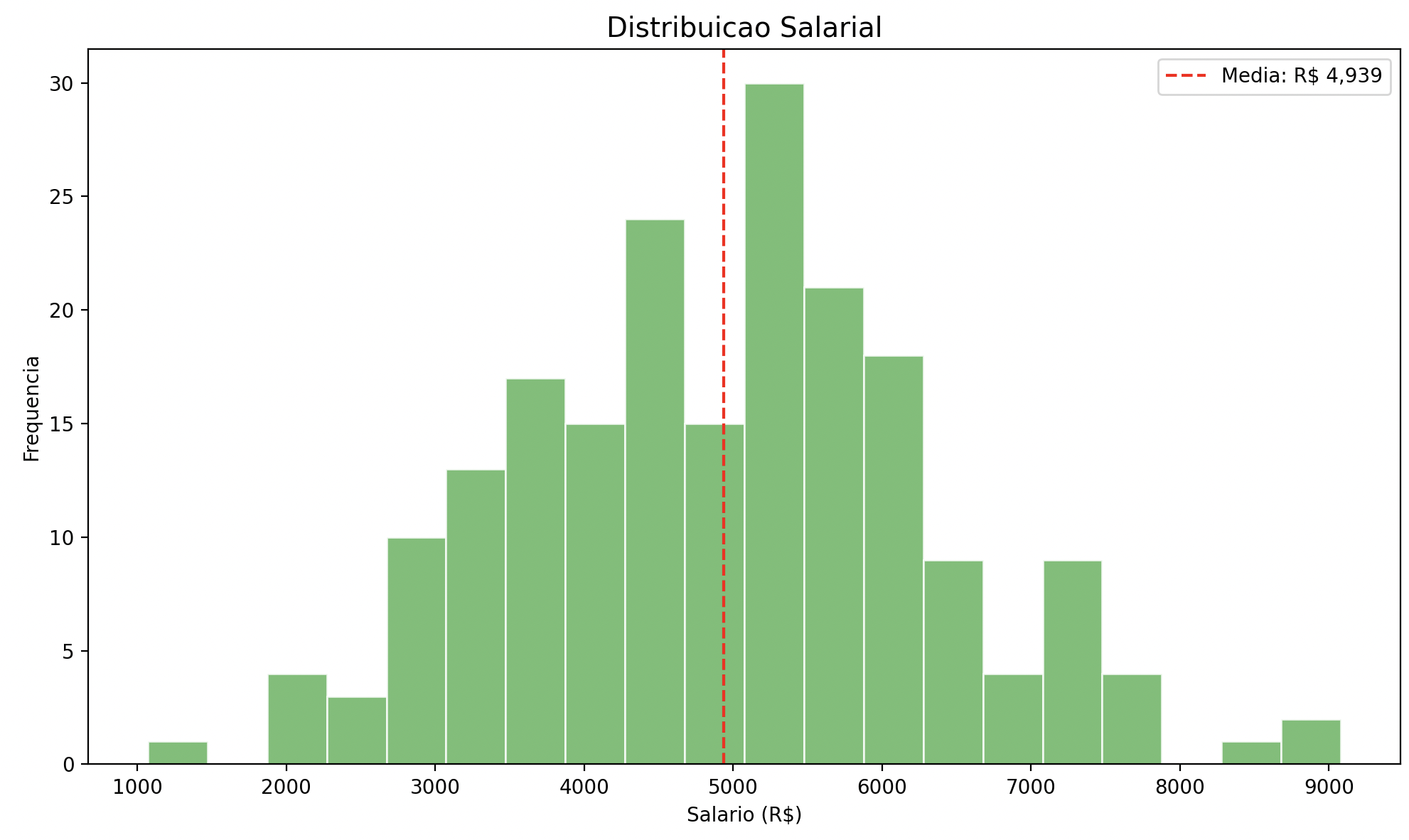
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(42)
salarios = np.random.normal(5000, 1500, 200)
plt.figure(figsize=(10, 6))
plt.hist(salarios, bins=20, color="#4CAF50", edgecolor="white", alpha=0.8)
plt.title("Distribuicao Salarial", fontsize=14)
plt.xlabel("Salario (R$)")
plt.ylabel("Frequencia")
plt.axvline(salarios.mean(), color="red", linestyle="--", label=f"Media: R$ {salarios.mean():,.0f}")
plt.legend()
plt.tight_layout()
plt.show()
Customização avançada
Subplots: vários gráficos em uma figura
import matplotlib.pyplot as plt
import numpy as np
meses = ["Jan", "Fev", "Mar", "Abr", "Mai", "Jun"]
vendas = [1200, 1500, 1350, 1800, 2100, 1950]
custos = [800, 900, 850, 1000, 1100, 1050]
lucro = [v - c for v, c in zip(vendas, custos)]
fig, axes = plt.subplots(1, 3, figsize=(16, 5))
# Grafico 1: Vendas
axes[0].plot(meses, vendas, marker="o", color="#2196F3")
axes[0].set_title("Vendas")
axes[0].set_ylabel("R$")
# Grafico 2: Custos
axes[1].bar(meses, custos, color="#FF9800")
axes[1].set_title("Custos")
axes[1].set_ylabel("R$")
# Grafico 3: Lucro
axes[2].bar(meses, lucro, color="#4CAF50")
axes[2].set_title("Lucro")
axes[2].set_ylabel("R$")
plt.suptitle("Dashboard Financeiro - 1o Semestre 2026", fontsize=16)
plt.tight_layout()
plt.show()
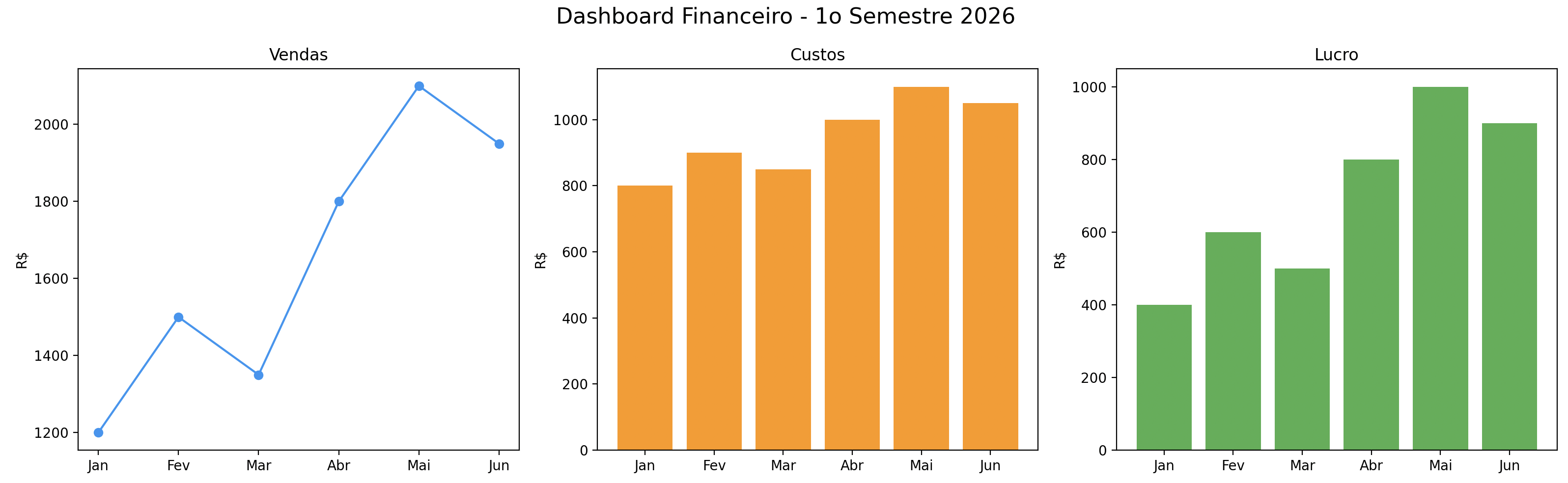
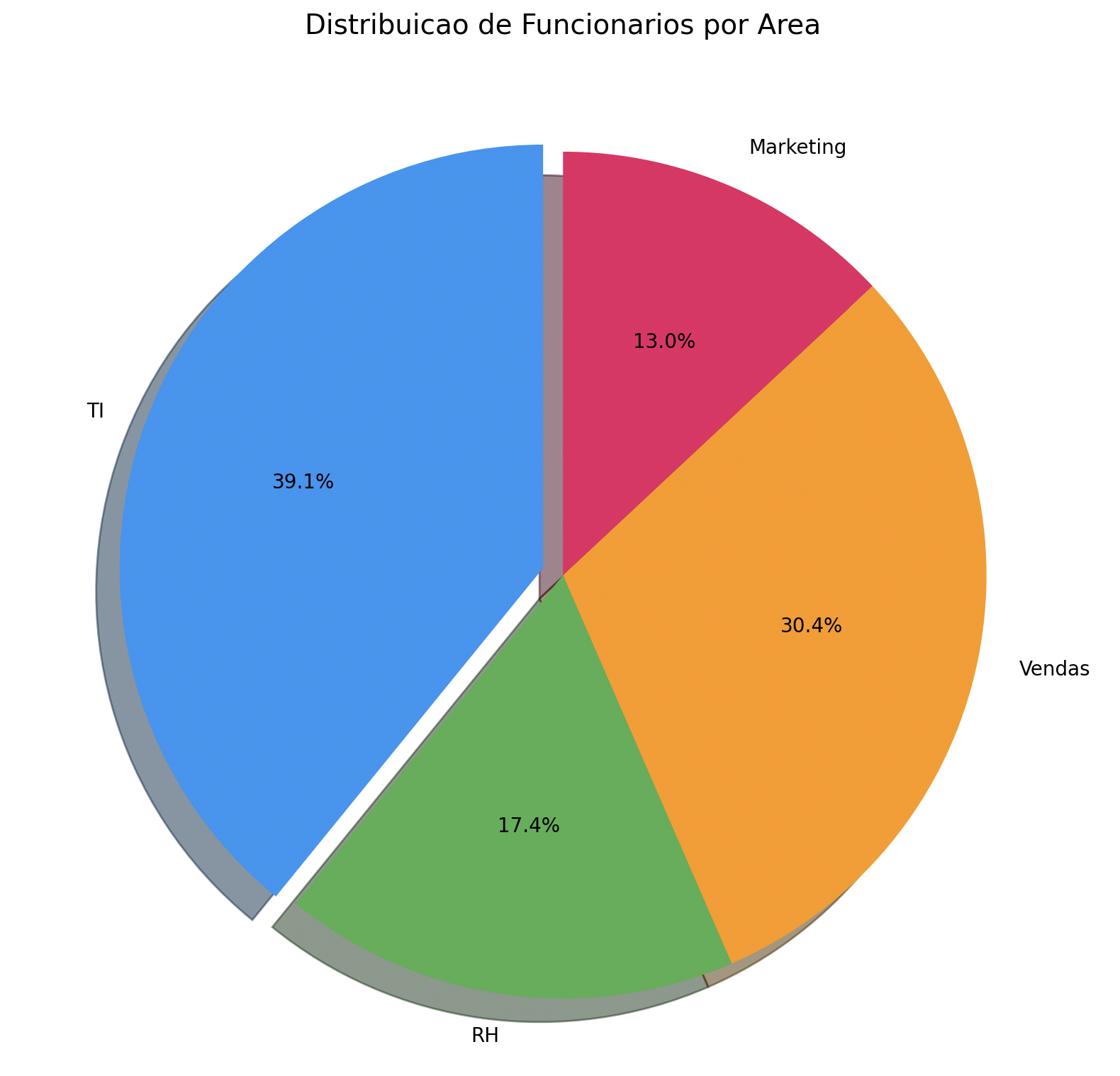
Gráfico de pizza
import matplotlib.pyplot as plt
categorias = ["TI", "RH", "Vendas", "Marketing"]
valores = [45, 20, 35, 15]
cores = ["#2196F3", "#4CAF50", "#FF9800", "#E91E63"]
explode = (0.05, 0, 0, 0) # Destacar a primeira fatia
plt.figure(figsize=(8, 8))
plt.pie(valores, labels=categorias, colors=cores, explode=explode,
autopct="%1.1f%%", startangle=90, shadow=True)
plt.title("Distribuicao de Funcionarios por Area", fontsize=14)
plt.tight_layout()
plt.show()
Seaborn: gráficos bonitos com menos código
Seaborn é construído sobre Matplotlib e oferece gráficos estatísticos com visual moderno. Ele funciona especialmente bem com DataFrames do Pandas.
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# Configurar estilo
sns.set_theme(style="whitegrid")
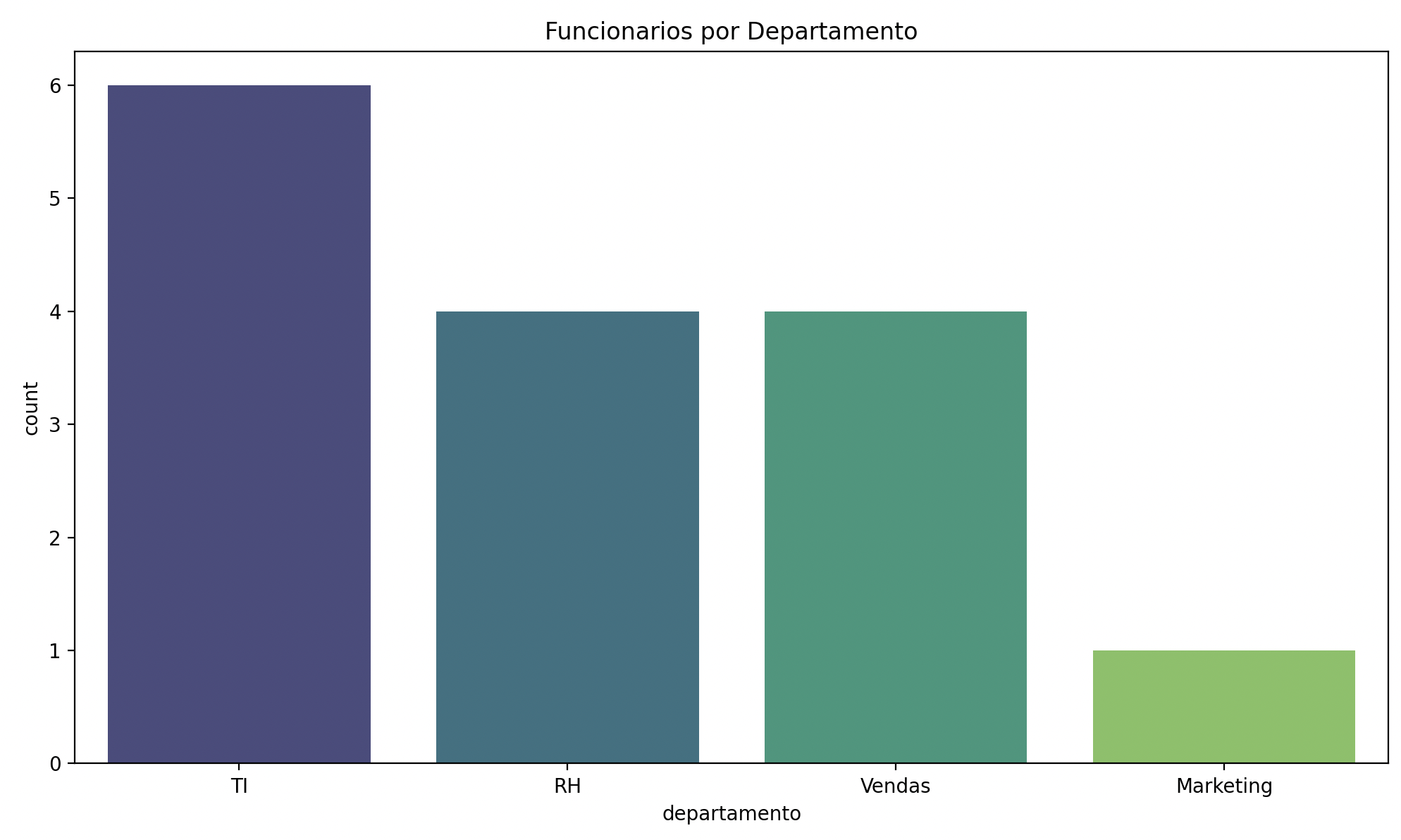
Countplot: contagem de categorias
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({
"departamento": ["TI", "RH", "TI", "Vendas", "RH",
"TI", "Vendas", "TI", "RH", "Vendas",
"TI", "Marketing", "RH", "TI", "Vendas"]
})
plt.figure(figsize=(10, 6))
sns.countplot(data=df, x="departamento", palette="viridis")
plt.title("Funcionarios por Departamento")
plt.tight_layout()
plt.show()
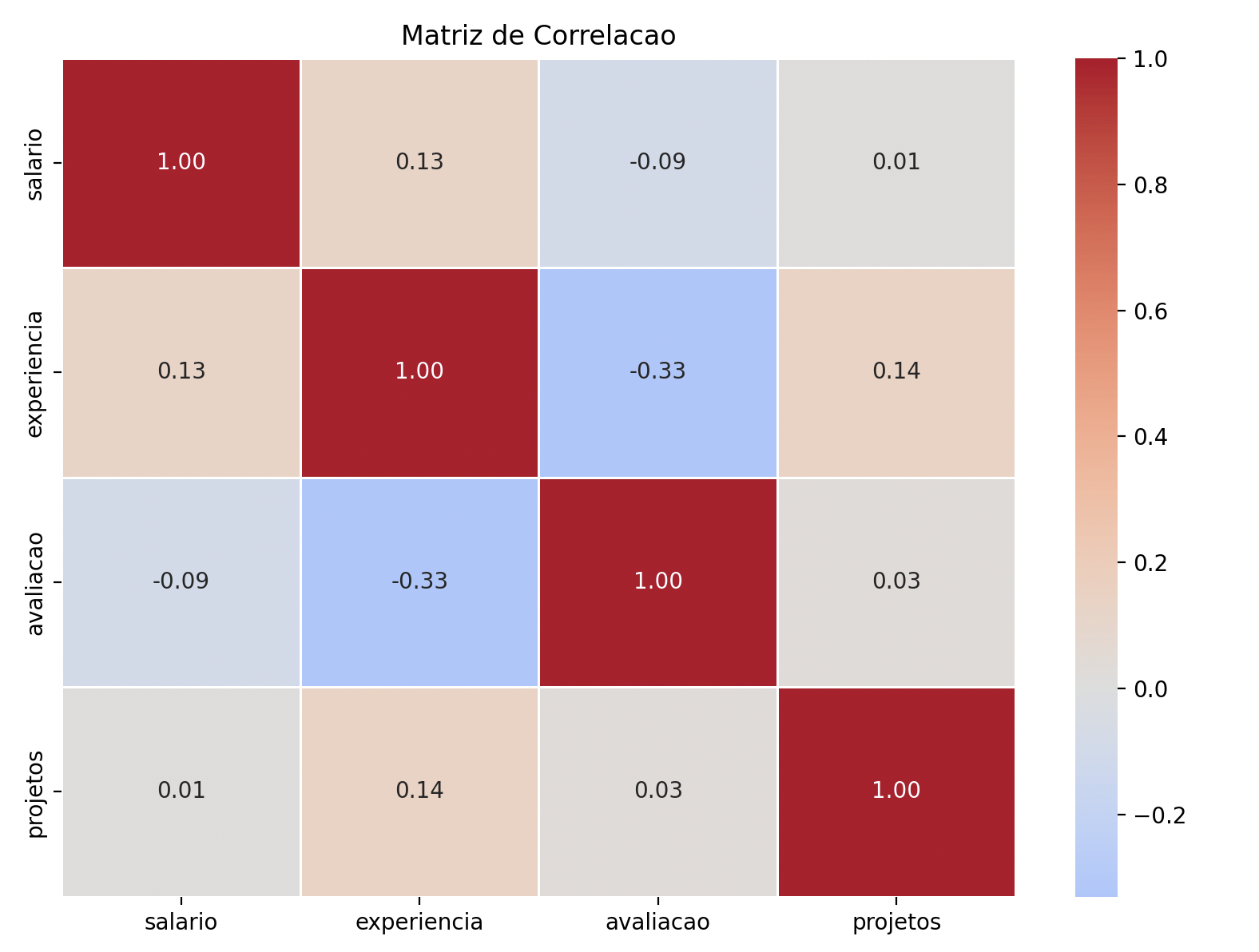
Heatmap: mapa de calor
Perfeito para visualizar correlações entre variáveis:
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
df = pd.DataFrame({
"salario": np.random.normal(5000, 1500, 100),
"experiencia": np.random.uniform(1, 15, 100),
"avaliacao": np.random.uniform(5, 10, 100),
"projetos": np.random.randint(1, 20, 100)
})
plt.figure(figsize=(8, 6))
correlacao = df.corr()
sns.heatmap(correlacao, annot=True, cmap="coolwarm", center=0,
fmt=".2f", linewidths=0.5)
plt.title("Matriz de Correlacao")
plt.tight_layout()
plt.show()
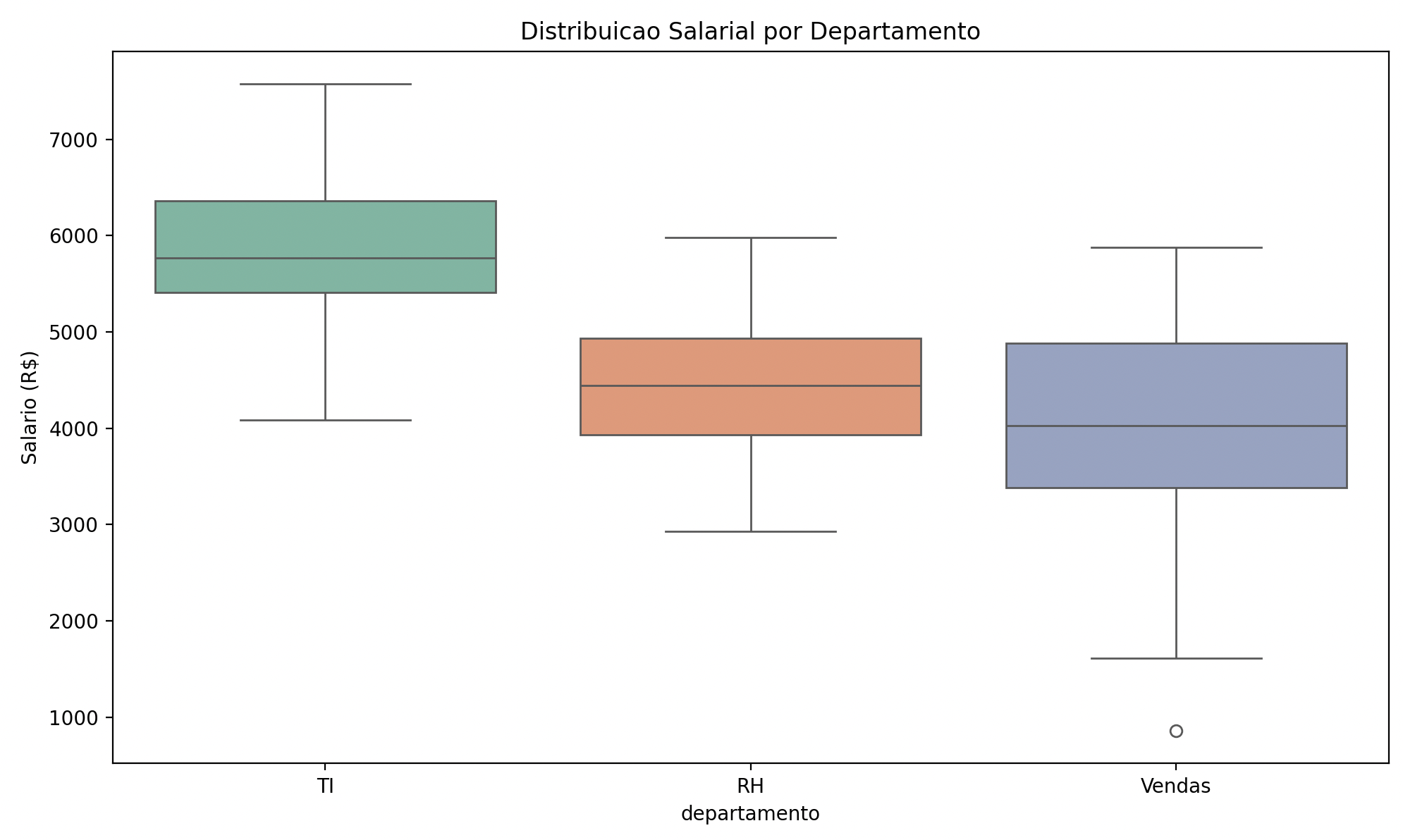
Boxplot: distribuição e outliers
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
df = pd.DataFrame({
"departamento": ["TI"] * 30 + ["RH"] * 30 + ["Vendas"] * 30,
"salario": np.concatenate([
np.random.normal(6000, 1000, 30),
np.random.normal(4500, 800, 30),
np.random.normal(4000, 1200, 30)
])
})
plt.figure(figsize=(10, 6))
sns.boxplot(data=df, x="departamento", y="salario", palette="Set2")
plt.title("Distribuicao Salarial por Departamento")
plt.ylabel("Salario (R$)")
plt.tight_layout()
plt.show()
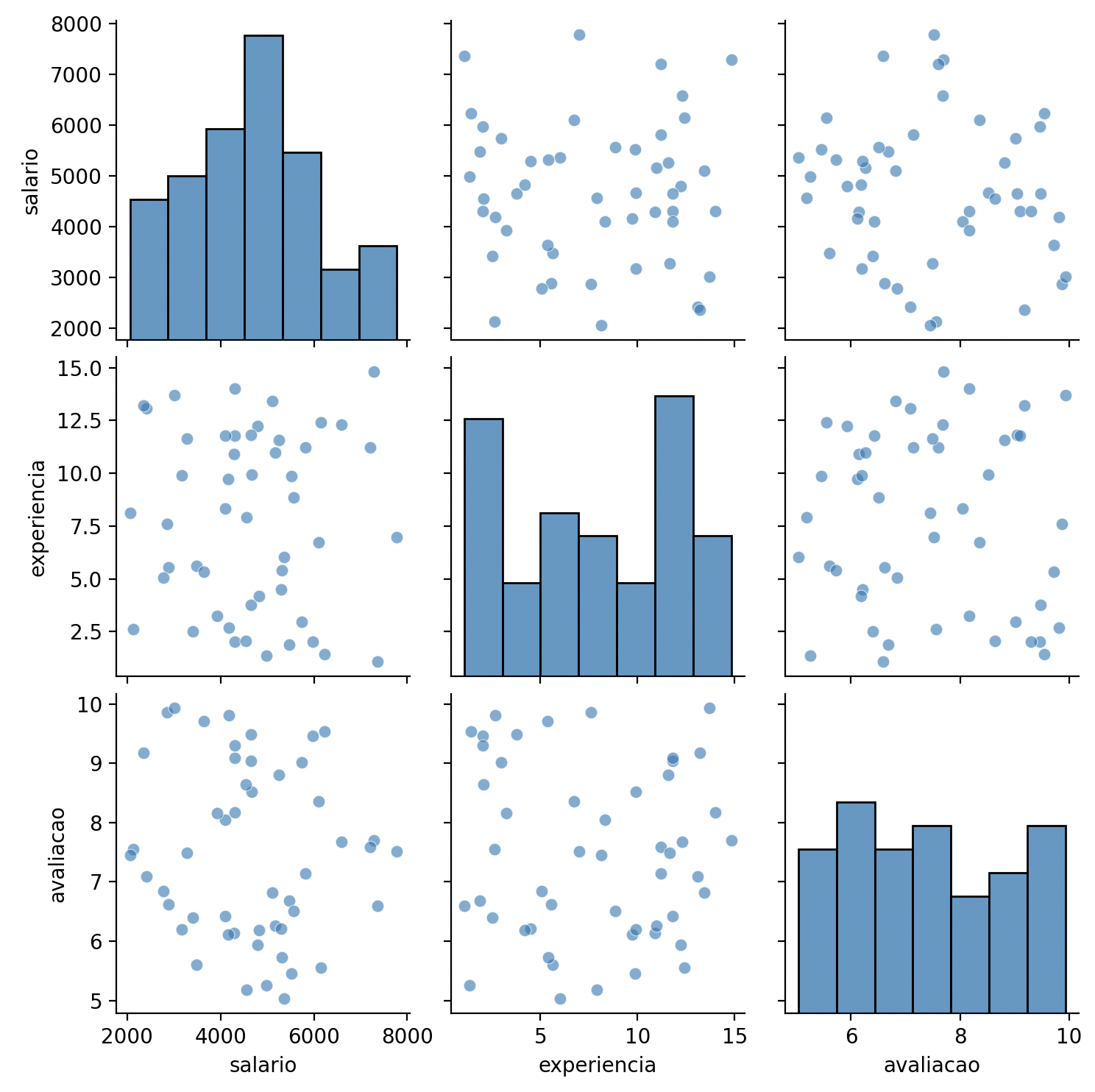
Pairplot: relações entre todas as variáveis
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
df = pd.DataFrame({
"salario": np.random.normal(5000, 1500, 50),
"experiencia": np.random.uniform(1, 15, 50),
"avaliacao": np.random.uniform(5, 10, 50)
})
sns.pairplot(df, diag_kind="hist", plot_kws={"alpha": 0.6})
plt.suptitle("Relacao entre Variaveis", y=1.02)
plt.show()
Salvando gráficos
Para salvar um gráfico em arquivo, use savefig() antes de show():
import matplotlib.pyplot as plt
meses = ["Jan", "Fev", "Mar", "Abr", "Mai", "Jun"]
vendas = [1200, 1500, 1350, 1800, 2100, 1950]
plt.figure(figsize=(10, 6))
plt.plot(meses, vendas, marker="o", color="#2196F3")
plt.title("Vendas Mensais")
# Salvar em diferentes formatos
plt.savefig("vendas.png", dpi=300, bbox_inches="tight")
plt.savefig("vendas.pdf", bbox_inches="tight")
plt.savefig("vendas.svg", bbox_inches="tight")
plt.show()
O parâmetro dpi=300 garante alta resolução. O bbox_inches="tight" remove espaços em branco ao redor do gráfico.
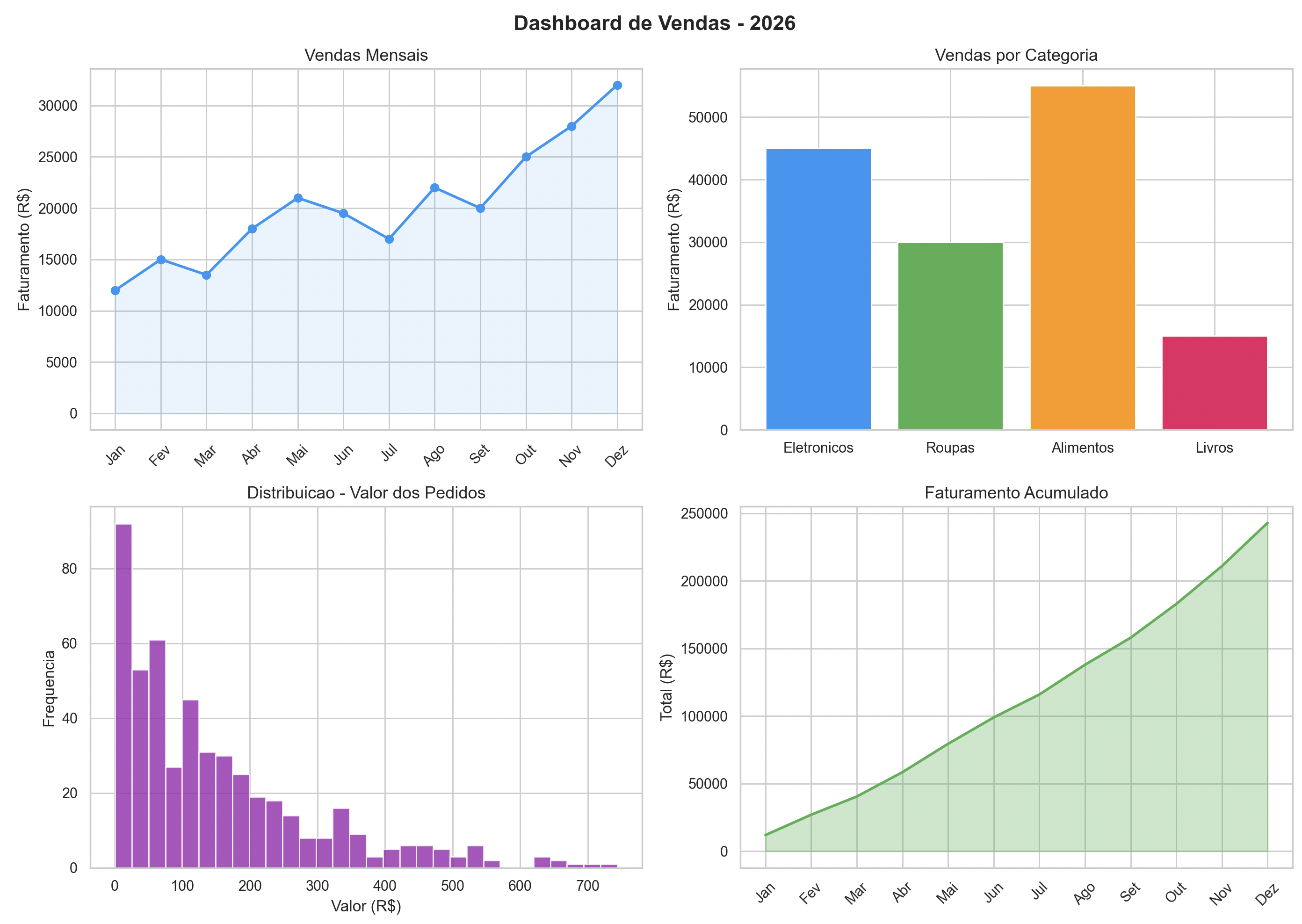
Exemplo prático: dashboard de vendas
Vamos criar um dashboard completo combinando Matplotlib e Seaborn:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
sns.set_theme(style="whitegrid")
np.random.seed(42)
# Criando dataset
meses = ["Jan", "Fev", "Mar", "Abr", "Mai", "Jun",
"Jul", "Ago", "Set", "Out", "Nov", "Dez"]
vendas_mensal = [12000, 15000, 13500, 18000, 21000, 19500,
17000, 22000, 20000, 25000, 28000, 32000]
categorias = ["Eletronicos", "Roupas", "Alimentos", "Livros"]
vendas_categoria = [45000, 30000, 55000, 15000]
# Criar figura com 4 subplots
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 1. Vendas mensais (linha)
axes[0, 0].plot(meses, vendas_mensal, marker="o", color="#2196F3", linewidth=2)
axes[0, 0].fill_between(range(len(meses)), vendas_mensal, alpha=0.1, color="#2196F3")
axes[0, 0].set_title("Vendas Mensais", fontsize=13)
axes[0, 0].set_ylabel("Faturamento (R$)")
axes[0, 0].tick_params(axis="x", rotation=45)
# 2. Vendas por categoria (barra)
cores = ["#2196F3", "#4CAF50", "#FF9800", "#E91E63"]
axes[0, 1].bar(categorias, vendas_categoria, color=cores)
axes[0, 1].set_title("Vendas por Categoria", fontsize=13)
axes[0, 1].set_ylabel("Faturamento (R$)")
# 3. Distribuicao de valores (histograma)
valores_pedidos = np.random.exponential(150, 500)
axes[1, 0].hist(valores_pedidos, bins=30, color="#9C27B0", edgecolor="white", alpha=0.8)
axes[1, 0].set_title("Distribuicao - Valor dos Pedidos", fontsize=13)
axes[1, 0].set_xlabel("Valor (R$)")
axes[1, 0].set_ylabel("Frequencia")
# 4. Crescimento acumulado (area)
acumulado = np.cumsum(vendas_mensal)
axes[1, 1].fill_between(range(len(meses)), acumulado, alpha=0.3, color="#4CAF50")
axes[1, 1].plot(range(len(meses)), acumulado, color="#4CAF50", linewidth=2)
axes[1, 1].set_xticks(range(len(meses)))
axes[1, 1].set_xticklabels(meses, rotation=45)
axes[1, 1].set_title("Faturamento Acumulado", fontsize=13)
axes[1, 1].set_ylabel("Total (R$)")
plt.suptitle("Dashboard de Vendas - 2026", fontsize=16, fontweight="bold")
plt.tight_layout()
plt.savefig("dashboard_vendas.png", dpi=300, bbox_inches="tight")
plt.show()
Resumo: quando usar cada gráfico
| Tipo de gráfico | Quando usar | Matplotlib | Seaborn |
|---|---|---|---|
| Linha | Tendências ao longo do tempo | plt.plot() |
sns.lineplot() |
| Barra | Comparar categorias | plt.bar() |
sns.barplot() |
| Dispersão | Relação entre 2 variáveis | plt.scatter() |
sns.scatterplot() |
| Histograma | Distribuição de dados | plt.hist() |
sns.histplot() |
| Boxplot | Distribuição + outliers | plt.boxplot() |
sns.boxplot() |
| Pizza | Proporções de um todo | plt.pie() |
— |
| Heatmap | Correlações | — | sns.heatmap() |
| Pairplot | Relações múltiplas | — | sns.pairplot() |
Conclusão
Matplotlib e Seaborn formam a dupla essencial para visualização de dados em Python. Matplotlib oferece controle total sobre cada elemento do gráfico, enquanto Seaborn entrega resultados bonitos com menos código. Na prática, os dois são usados juntos: Seaborn para gráficos estatísticos rápidos e Matplotlib para personalização fina. No próximo artigo, vamos colocar tudo em prática com um projeto completo de análise de dados.