Projeto: análise de dados com Python na prática
Projeto completo de análise de dados: carregue, limpe, analise e visualize um dataset real com Python.
O projeto
Neste artigo, vamos reunir tudo o que aprendemos na trilha de Data Science e criar um projeto completo de análise de dados. Vamos seguir o fluxo profissional: definir uma pergunta, carregar os dados, limpar, analisar e visualizar os resultados.
O nosso dataset será um registro de vendas de uma loja online fictícia ao longo de um ano. Vamos criar os dados diretamente no código para que você possa reproduzir tudo sem precisar baixar arquivos.
As perguntas que queremos responder
Antes de começar qualquer análise, é fundamental definir as perguntas de negócio:
- Qual foi o faturamento total e o ticket médio?
- Quais são os meses com maior e menor faturamento?
- Qual categoria de produto gera mais receita?
- Existe diferença de desempenho entre as regiões?
- Qual é o perfil dos pedidos (distribuição de valores)?
Etapa 1: Configuração e criação do dataset
Primeiro, vamos importar as bibliotecas e criar nosso dataset:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Configuracoes visuais
sns.set_theme(style="whitegrid")
plt.rcParams["figure.figsize"] = (12, 6)
np.random.seed(42)
# Criando o dataset de vendas
n_registros = 500
# Gerar datas ao longo de 2025
datas = pd.date_range("2025-01-01", "2025-12-31", periods=n_registros)
# Categorias e produtos
categorias_produtos = {
"Eletronicos": ["Notebook", "Smartphone", "Tablet", "Fone Bluetooth"],
"Roupas": ["Camiseta", "Calca Jeans", "Jaqueta", "Tenis"],
"Casa": ["Luminaria", "Travesseiro", "Organizador", "Tapete"],
"Livros": ["Ficcao", "Tecnico", "Autoajuda", "Biografia"]
}
# Faixas de preco por categoria
faixa_preco = {
"Eletronicos": (200, 5000),
"Roupas": (50, 400),
"Casa": (30, 300),
"Livros": (25, 120)
}
regioes = ["Sudeste", "Sul", "Nordeste", "Norte", "Centro-Oeste"]
peso_regioes = [0.40, 0.20, 0.20, 0.10, 0.10]
# Gerar dados aleatorios
registros = []
for i in range(n_registros):
categoria = np.random.choice(list(categorias_produtos.keys()),
p=[0.35, 0.25, 0.25, 0.15])
produto = np.random.choice(categorias_produtos[categoria])
preco_min, preco_max = faixa_preco[categoria]
preco = round(np.random.uniform(preco_min, preco_max), 2)
quantidade = np.random.randint(1, 6)
regiao = np.random.choice(regioes, p=peso_regioes)
registros.append({
"data": datas[i],
"categoria": categoria,
"produto": produto,
"preco_unitario": preco,
"quantidade": quantidade,
"regiao": regiao
})
df = pd.DataFrame(registros)
print(f"Dataset criado: {df.shape[0]} registros, {df.shape[1]} colunas")
print(df.head(10))
Etapa 2: Exploração inicial
Antes de analisar, precisamos conhecer os dados:
# Informacoes gerais
print("=== Informacoes do Dataset ===")
print(df.info())
print()
# Estatisticas descritivas
print("=== Estatisticas Numericas ===")
print(df.describe().round(2))
print()
# Valores unicos por coluna categorica
print("=== Valores Unicos ===")
print(f"Categorias: {df['categoria'].nunique()} -> {df['categoria'].unique()}")
print(f"Produtos: {df['produto'].nunique()}")
print(f"Regioes: {df['regiao'].nunique()} -> {df['regiao'].unique()}")
print()
# Verificar valores nulos
print("=== Valores Nulos ===")
print(df.isna().sum())
Etapa 3: Limpeza e preparação
Nosso dataset está limpo (nós o criamos!), mas em projetos reais essa etapa é crucial. Vamos adicionar algumas imperfeições e corrigi-las para simular o mundo real:
# Simular dados sujos: adicionar valores nulos e duplicatas
df_sujo = df.copy()
# Inserir 10 valores nulos aleatorios na coluna preco_unitario
indices_nulos = np.random.choice(df_sujo.index, size=10, replace=False)
df_sujo.loc[indices_nulos, "preco_unitario"] = np.nan
# Inserir 5 linhas duplicadas
duplicatas = df_sujo.sample(5)
df_sujo = pd.concat([df_sujo, duplicatas], ignore_index=True)
print(f"Registros antes da limpeza: {len(df_sujo)}")
print(f"Valores nulos: {df_sujo['preco_unitario'].isna().sum()}")
print(f"Duplicatas: {df_sujo.duplicated().sum()}")
print()
# LIMPEZA
# 1. Remover duplicatas
df_limpo = df_sujo.drop_duplicates()
print(f"Apos remover duplicatas: {len(df_limpo)} registros")
# 2. Preencher nulos com a mediana da categoria
df_limpo["preco_unitario"] = df_limpo.groupby("categoria")["preco_unitario"].transform(
lambda x: x.fillna(x.median())
)
print(f"Nulos restantes: {df_limpo['preco_unitario'].isna().sum()}")
# 3. Criar colunas calculadas
df_limpo["faturamento"] = df_limpo["preco_unitario"] * df_limpo["quantidade"]
df_limpo["mes"] = df_limpo["data"].dt.month
df_limpo["nome_mes"] = df_limpo["data"].dt.strftime("%b")
print(f"\nDataset limpo: {df_limpo.shape[0]} registros, {df_limpo.shape[1]} colunas")
print(df_limpo.head())
A partir daqui, vamos usar df_limpo como nosso DataFrame principal. Em vez de carregar os dados sujos, vamos simplificar usando o DataFrame original já preparado:
# Para o restante da analise, usamos o df original com as colunas extras
df["faturamento"] = df["preco_unitario"] * df["quantidade"]
df["mes"] = df["data"].dt.month
df["nome_mes"] = df["data"].dt.strftime("%b")
Etapa 4: Análise — respondendo as perguntas
Pergunta 1: Faturamento total e ticket médio
faturamento_total = df["faturamento"].sum()
ticket_medio = df["faturamento"].mean()
total_pedidos = len(df)
total_itens = df["quantidade"].sum()
print("=== Resumo Geral ===")
print(f"Total de pedidos: {total_pedidos}")
print(f"Total de itens vendidos: {total_itens}")
print(f"Faturamento total: R$ {faturamento_total:,.2f}")
print(f"Ticket medio: R$ {ticket_medio:,.2f}")
print(f"Preco unitario medio: R$ {df['preco_unitario'].mean():,.2f}")
Pergunta 2: Faturamento por mês
faturamento_mensal = df.groupby("mes")["faturamento"].sum().reset_index()
nomes_meses = ["Jan", "Fev", "Mar", "Abr", "Mai", "Jun",
"Jul", "Ago", "Set", "Out", "Nov", "Dez"]
faturamento_mensal["nome_mes"] = faturamento_mensal["mes"].apply(lambda x: nomes_meses[x - 1])
print("=== Faturamento Mensal ===")
print(faturamento_mensal[["nome_mes", "faturamento"]].to_string(index=False))
melhor_mes = faturamento_mensal.loc[faturamento_mensal["faturamento"].idxmax()]
pior_mes = faturamento_mensal.loc[faturamento_mensal["faturamento"].idxmin()]
print(f"\nMelhor mes: {melhor_mes['nome_mes']} (R$ {melhor_mes['faturamento']:,.2f})")
print(f"Pior mes: {pior_mes['nome_mes']} (R$ {pior_mes['faturamento']:,.2f})")
Pergunta 3: Receita por categoria
receita_categoria = df.groupby("categoria").agg({
"faturamento": "sum",
"quantidade": "sum",
"preco_unitario": "mean"
}).round(2).sort_values("faturamento", ascending=False)
receita_categoria["percentual"] = (
receita_categoria["faturamento"] / receita_categoria["faturamento"].sum() * 100
).round(1)
print("=== Receita por Categoria ===")
print(receita_categoria)
Pergunta 4: Desempenho por região
desempenho_regiao = df.groupby("regiao").agg({
"faturamento": ["sum", "mean", "count"]
}).round(2)
desempenho_regiao.columns = ["faturamento_total", "ticket_medio", "num_pedidos"]
desempenho_regiao = desempenho_regiao.sort_values("faturamento_total", ascending=False)
print("=== Desempenho por Regiao ===")
print(desempenho_regiao)
Pergunta 5: Top 10 produtos
top_produtos = df.groupby("produto").agg({
"faturamento": "sum",
"quantidade": "sum"
}).sort_values("faturamento", ascending=False).head(10)
print("=== Top 10 Produtos ===")
print(top_produtos)
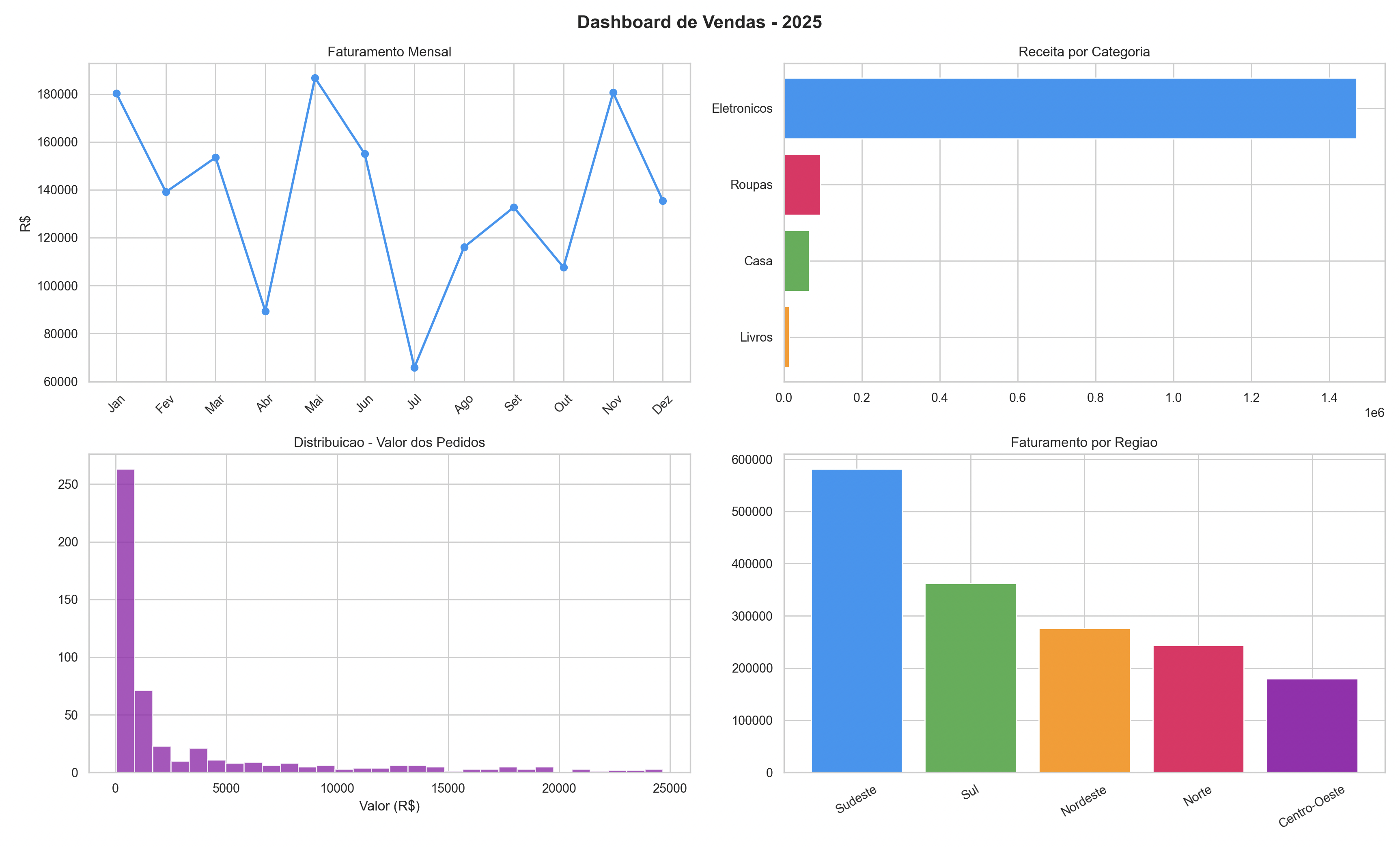
Etapa 5: Visualização
Agora vamos transformar os números em gráficos:
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# 1. Faturamento mensal (linha)
fat_mensal = df.groupby("mes")["faturamento"].sum()
axes[0, 0].plot(nomes_meses[:len(fat_mensal)], fat_mensal.values,
marker="o", color="#2196F3", linewidth=2)
axes[0, 0].fill_between(range(len(fat_mensal)), fat_mensal.values,
alpha=0.1, color="#2196F3")
axes[0, 0].set_title("Faturamento Mensal", fontsize=13)
axes[0, 0].set_ylabel("R$")
axes[0, 0].tick_params(axis="x", rotation=45)
# 2. Receita por categoria (barra)
cat_fat = df.groupby("categoria")["faturamento"].sum().sort_values(ascending=True)
cores_cat = ["#FF9800", "#4CAF50", "#E91E63", "#2196F3"]
axes[0, 1].barh(cat_fat.index, cat_fat.values, color=cores_cat)
axes[0, 1].set_title("Receita por Categoria", fontsize=13)
axes[0, 1].set_xlabel("Faturamento (R$)")
# 3. Distribuicao dos pedidos (histograma)
axes[0, 2].hist(df["faturamento"], bins=30, color="#9C27B0",
edgecolor="white", alpha=0.8)
axes[0, 2].axvline(df["faturamento"].mean(), color="red",
linestyle="--", label=f"Media: R$ {df['faturamento'].mean():,.0f}")
axes[0, 2].set_title("Distribuicao - Valor dos Pedidos", fontsize=13)
axes[0, 2].set_xlabel("Valor (R$)")
axes[0, 2].legend()
# 4. Faturamento por regiao (barra)
reg_fat = df.groupby("regiao")["faturamento"].sum().sort_values(ascending=False)
cores_reg = ["#2196F3", "#4CAF50", "#FF9800", "#E91E63", "#9C27B0"]
axes[1, 0].bar(reg_fat.index, reg_fat.values, color=cores_reg)
axes[1, 0].set_title("Faturamento por Regiao", fontsize=13)
axes[1, 0].set_ylabel("R$")
axes[1, 0].tick_params(axis="x", rotation=30)
# 5. Top 5 produtos (barra horizontal)
top5 = df.groupby("produto")["faturamento"].sum().sort_values(ascending=True).tail(5)
axes[1, 1].barh(top5.index, top5.values, color="#00BCD4")
axes[1, 1].set_title("Top 5 Produtos", fontsize=13)
axes[1, 1].set_xlabel("Faturamento (R$)")
# 6. Quantidade por categoria (pizza)
qtd_cat = df.groupby("categoria")["quantidade"].sum()
axes[1, 2].pie(qtd_cat.values, labels=qtd_cat.index, autopct="%1.1f%%",
colors=["#2196F3", "#4CAF50", "#FF9800", "#E91E63"],
startangle=90)
axes[1, 2].set_title("Itens Vendidos por Categoria", fontsize=13)
plt.suptitle("Dashboard de Vendas - Loja Online 2025",
fontsize=16, fontweight="bold")
plt.tight_layout()
plt.savefig("dashboard_analise_completa.png", dpi=300, bbox_inches="tight")
plt.show()
Gráfico extra: heatmap de vendas por mês e categoria
# Tabela cruzada: mes x categoria
tabela_cruzada = df.pivot_table(
values="faturamento",
index="categoria",
columns="mes",
aggfunc="sum"
).round(0)
# Renomear colunas para nomes de meses
tabela_cruzada.columns = nomes_meses[:len(tabela_cruzada.columns)]
plt.figure(figsize=(14, 6))
sns.heatmap(tabela_cruzada, annot=True, fmt=",.0f", cmap="YlOrRd",
linewidths=0.5, cbar_kws={"label": "Faturamento (R$)"})
plt.title("Faturamento por Categoria e Mes", fontsize=14)
plt.ylabel("Categoria")
plt.xlabel("Mes")
plt.tight_layout()
plt.savefig("heatmap_vendas.png", dpi=300, bbox_inches="tight")
plt.show()
Gráfico extra: boxplot comparativo
plt.figure(figsize=(12, 6))
sns.boxplot(data=df, x="categoria", y="faturamento", palette="Set2")
plt.title("Distribuicao do Faturamento por Categoria", fontsize=14)
plt.xlabel("Categoria")
plt.ylabel("Faturamento por Pedido (R$)")
plt.tight_layout()
plt.show()
Etapa 6: Conclusões
Depois de toda a análise, chegamos às nossas descobertas. Num projeto real, esta é a parte que você apresenta para o time de negócio:
print("=" * 60)
print("RELATORIO FINAL - ANALISE DE VENDAS 2025")
print("=" * 60)
print(f"""
1. FATURAMENTO
- Total: R$ {df['faturamento'].sum():,.2f}
- Ticket medio: R$ {df['faturamento'].mean():,.2f}
- Total de pedidos: {len(df)}
2. SAZONALIDADE
- Melhor mes: {melhor_mes['nome_mes']} (R$ {melhor_mes['faturamento']:,.2f})
- Pior mes: {pior_mes['nome_mes']} (R$ {pior_mes['faturamento']:,.2f})
3. CATEGORIAS
- Eletronicos lidera em faturamento (maior preco unitario)
- Livros tem menor participacao no faturamento
4. REGIOES
- Sudeste concentra a maior parte das vendas
- Norte e Centro-Oeste tem potencial de crescimento
5. RECOMENDACOES
- Investir em campanhas no Sudeste (maior volume)
- Explorar potencial de crescimento no Norte e Centro-Oeste
- Aumentar estoque de eletronicos nos meses de pico
""")
Script completo
Para facilitar, aqui está o código completo em um único arquivo que você pode copiar e executar:
"""
Projeto: Analise de Vendas - Loja Online 2025
Trilha: Data Science com Python
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# === CONFIGURACAO ===
sns.set_theme(style="whitegrid")
plt.rcParams["figure.figsize"] = (12, 6)
np.random.seed(42)
# === CRIACAO DO DATASET ===
n_registros = 500
datas = pd.date_range("2025-01-01", "2025-12-31", periods=n_registros)
categorias_produtos = {
"Eletronicos": ["Notebook", "Smartphone", "Tablet", "Fone Bluetooth"],
"Roupas": ["Camiseta", "Calca Jeans", "Jaqueta", "Tenis"],
"Casa": ["Luminaria", "Travesseiro", "Organizador", "Tapete"],
"Livros": ["Ficcao", "Tecnico", "Autoajuda", "Biografia"]
}
faixa_preco = {
"Eletronicos": (200, 5000),
"Roupas": (50, 400),
"Casa": (30, 300),
"Livros": (25, 120)
}
regioes = ["Sudeste", "Sul", "Nordeste", "Norte", "Centro-Oeste"]
peso_regioes = [0.40, 0.20, 0.20, 0.10, 0.10]
registros = []
for i in range(n_registros):
categoria = np.random.choice(list(categorias_produtos.keys()),
p=[0.35, 0.25, 0.25, 0.15])
produto = np.random.choice(categorias_produtos[categoria])
preco_min, preco_max = faixa_preco[categoria]
preco = round(np.random.uniform(preco_min, preco_max), 2)
quantidade = np.random.randint(1, 6)
regiao = np.random.choice(regioes, p=peso_regioes)
registros.append({
"data": datas[i],
"categoria": categoria,
"produto": produto,
"preco_unitario": preco,
"quantidade": quantidade,
"regiao": regiao
})
df = pd.DataFrame(registros)
df["faturamento"] = df["preco_unitario"] * df["quantidade"]
df["mes"] = df["data"].dt.month
df["nome_mes"] = df["data"].dt.strftime("%b")
# === ANALISE ===
print("=" * 50)
print("ANALISE DE VENDAS - LOJA ONLINE 2025")
print("=" * 50)
print(f"\nTotal de pedidos: {len(df)}")
print(f"Faturamento total: R$ {df['faturamento'].sum():,.2f}")
print(f"Ticket medio: R$ {df['faturamento'].mean():,.2f}")
print("\n--- Faturamento por Categoria ---")
cat_resumo = df.groupby("categoria")["faturamento"].sum().sort_values(ascending=False)
for cat, valor in cat_resumo.items():
print(f" {cat}: R$ {valor:,.2f}")
print("\n--- Faturamento por Regiao ---")
reg_resumo = df.groupby("regiao")["faturamento"].sum().sort_values(ascending=False)
for reg, valor in reg_resumo.items():
print(f" {reg}: R$ {valor:,.2f}")
# === VISUALIZACAO ===
nomes_meses = ["Jan", "Fev", "Mar", "Abr", "Mai", "Jun",
"Jul", "Ago", "Set", "Out", "Nov", "Dez"]
fig, axes = plt.subplots(2, 2, figsize=(16, 10))
# Faturamento mensal
fat_mensal = df.groupby("mes")["faturamento"].sum()
axes[0, 0].plot(nomes_meses[:len(fat_mensal)], fat_mensal.values,
marker="o", color="#2196F3", linewidth=2)
axes[0, 0].set_title("Faturamento Mensal")
axes[0, 0].set_ylabel("R$")
axes[0, 0].tick_params(axis="x", rotation=45)
# Receita por categoria
cat_fat = df.groupby("categoria")["faturamento"].sum().sort_values(ascending=True)
axes[0, 1].barh(cat_fat.index, cat_fat.values,
color=["#FF9800", "#4CAF50", "#E91E63", "#2196F3"])
axes[0, 1].set_title("Receita por Categoria")
# Distribuicao dos pedidos
axes[1, 0].hist(df["faturamento"], bins=30, color="#9C27B0",
edgecolor="white", alpha=0.8)
axes[1, 0].set_title("Distribuicao - Valor dos Pedidos")
axes[1, 0].set_xlabel("Valor (R$)")
# Faturamento por regiao
reg_fat = df.groupby("regiao")["faturamento"].sum().sort_values(ascending=False)
axes[1, 1].bar(reg_fat.index, reg_fat.values,
color=["#2196F3", "#4CAF50", "#FF9800", "#E91E63", "#9C27B0"])
axes[1, 1].set_title("Faturamento por Regiao")
axes[1, 1].tick_params(axis="x", rotation=30)
plt.suptitle("Dashboard de Vendas - 2025", fontsize=16, fontweight="bold")
plt.tight_layout()
plt.savefig("dashboard_vendas_2025.png", dpi=300, bbox_inches="tight")
plt.show()
print("\nDashboard salvo em 'dashboard_vendas_2025.png'")
O que você aprendeu nesta trilha
| Artigo | Ferramenta | Habilidade |
|---|---|---|
| Introdução a Data Science | Visão geral | Entender o fluxo e o ecossistema |
| NumPy | numpy |
Arrays, operações vetorizadas, agregações |
| Pandas | pandas |
Carregar, limpar, filtrar e agrupar dados |
| Matplotlib e Seaborn | matplotlib, seaborn |
Criar gráficos e dashboards |
| Projeto (este artigo) | Todas | Análise completa do início ao fim |
Próximos passos
Agora que você completou a trilha de Data Science com Python, pode seguir em várias direções:
- Machine Learning — Use Scikit-learn para criar modelos preditivos
- Datasets reais — Explore o Kaggle (kaggle.com) para praticar com dados de verdade
- SQL — Aprenda a extrair dados de bancos de dados relacionais
- Streamlit — Transforme suas análises em aplicações web interativas
- Deep Learning — Explore redes neurais com TensorFlow ou PyTorch
Conclusão
Parabéns por completar a trilha de Data Science com Python! Você saiu do zero e chegou a um projeto completo de análise de dados, passando por NumPy, Pandas, Matplotlib e Seaborn. O mais importante agora é praticar: pegue um dataset que te interesse, defina perguntas e tente respondê-las com código. Cada análise que você fizer vai consolidar seu conhecimento e te tornar um cientista de dados melhor.